ElasticSearch tutorial part I: ElasticSearch data mapping
Developer resources

Table of content
One of our core technologies we build upon here at LingoHub is Elasticsearch (ES). Built on top of the Apache Lucene project, ES provides extremely powerful text analysis and search capabilities that make it the ideal solution for the various text search requirements in our business.
In this small series of articles we want to write about how we use ES in our application starting with a small introduction to ElasticSearch data mapping.
Lucene basically stores documents internally as key-value pairs and ES extends this very low level storage mechanism by providing a document centric view on the internal data. Mapping the data model from a persistent storage location (usually a RDBMS) to an according JSON document structure that can be indexed in ES can be a bit tricky and there are a few things to consider when coming up with such a mapping.
In this article we have a look at how we represent and map our data from a relational DB to ES in order to be able to provide our users with a state of the art text search experience.
One of our core data structures here at LingoHub is a “translation” entity. Such a translation basically represents some arbitrary text fragment that has to be translated to various target languages. Our customers manage translation projects and each such project holds a myriad of translations which in turn consist of various phrases, so a simplified DB schema representing this entity looks as follows:
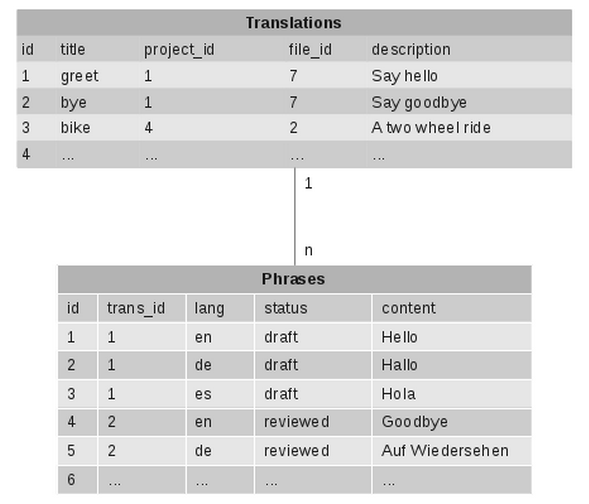
So each translation has a globally unique artifical ID and can be identified by a unique (per project) title. Each translation consists of multiple phrases (one per language) which have a globally unique ID as well.
Of course the translators working on a project need to be able to search for text content – both in the translation title and description itself as well as across the content of the various languages.
So the first thing we looked at was how we could efficiently map our one to many relationship to an according JSON data structure that can be indexed in ES.
As pointed out under Elasticsearch blog there are various ways to represent such a relationship in ES, with the following options being viable for our use case:
Nested objects
Parent / Child documents
Denormalization
To make a long story short we decided to go with option 1 for the following reasons:
search performance: nested documents are joined during index time and stored in the same lucene block so queries are faster than with parent-child relationships
the parent (translation) document contains overall status fields calculated from the child (phrase) documents, so updating the parent doc is necessary whenever a child document changes anyways
sorting and scoring: we want to be able to sort search results based on various field values in the parent and child documents
updates of translations have to be atomic
Especially point 4 is very important for us. ES provides no real transaction handling mechanism, e.g. if we want to update three phrases at the same time using a bulk update and the update fails for one phrase our index would be in an inconsistent state for the according translation. This cannot happen if a translation and all it’s phrases have to be indexed as one single document – the update of a translation document either succeeds or fails.
In order to be able to add documents to an ES index you have to tell ES what the documents to add look like and how they should be handled during indexing. This is achieved using a so called mapping definition.
What do all the settings in our mapping definition actually mean? Let’s go through them step by step starting with the general document properties
The _routing setting defines how indexed documents are routed to shards in ES. The article at http://www.elasticsearch.org/blog/customizing-your-document-routing/ provides an excellent overview why custom routing may be useful. In our case we decided that we want all documents from the same project to end up at the same shard to improve search performance and scale in the future.
Each indexed document is stored under a unique (per index and mapping) ID in ES. Per default ES creates this ID for you but we want our translation documents to have the same ID as in the translations table, in this way it is much easier to fetch documents from ES using the DB ID and vice versa.
By default ES adds all indexed fields to a special _all field which acts as the default search target in case no explicit field is specified during search. Since we do not require this feature we disable the _all field to save space and indexing time.
By default a mapping definition just tells ES how to handle the defined fields during indexing time, it is still possible to index documents that do not exactly match the defined structure, in which case ES will try to guess the type and per default index the field. Since we want complete control over the defined document structure we set the dynamic property to strict – in this way it is e.g. not possible to index documents that contain additional fields that are not defined in our mapping.
In the properties section we define all the fields that make up the content of the parent (i.e. the translation) document. For each field we define the type and how ES should handle indexing. Only the fields on which we actually want to perform text search are analyzed in our documents, for all others the values are indexed verbatim as we only want to filter on them i.e. performing queries with exact matches.
The “phrases” field represents the actual nested type definition which is achieved by setting the type to nested (makes sense, doesn’t it? ;-). Similar to the “translation” mapping the “phrases” mapping is represented as an own type in our ES index and in fact all nested documents are indexed as separate documents.
The important part about nested documents is that you can have an array of phrase documents in your translation document and in contrast to an embedded object the fields of the documents are not flattened during indexing so you are able to query each nested document independently. (see http://www.elasticsearch.org/guide/en/elasticsearch/reference/current/mapping-nested-type.html#mapping-nested-type)
Of course this approach of representing our data in ES also has it’s downsides. Two of the biggest issues are:
Nested documents cannot be updated independently from the parent document so updates are generally more expensive (more data to send)
Search queries are more complex as we have to use the special nested queries and filters to search in nested documents (more on searching in an upcoming article in this series)
In this article we have seen how we map our relational DB schema to an according data structure that can be indexed in ES. You may have noticed that we defined custom analyzers in our mapping definition for the fields on which we want to perform an actual text search and even have fields indexed more than once with different analyzers. In the next article we will have a look at the analysis process, why we choose to define our own analyzers and what they actually look like.

Dev Bit: How to add plugins to elasticsearch under Mac/Brew
Learn how to install Elasticsearch plugins on Mac with Homebrew, find the right libexec path, and verify plugins like Kopf or Elastic HQ.
Internationalization Programming - new i18n tutorial series
Learn internationalization best practices for popular programming languages. Discover common challenges and build applications ready for localization.

PHP internationalization - i18n mechanisms tutorial
Looking for effective PHP internationalization with fewer hassles? We found the solution that will help you. Learn more inside our blog

PHP internationalization with gettext tutorial
What is it, GNU gettext? How the PHP internationalization with gettext works? Read all info in our blog.
)