The ultimate guide to ISO language codes
Localization workflows & operations

Table of content
ISO language codes exist to allow the international community to successfully identify languages, dialects, and even language scripts. Most notably, language codes now play a crucial role in machine learning.
While there are many published language lists, different lists nowadays greatly depend and take from one another. Here are the most relevant language lists with language codes out there right now.
The Ethnologue is an annual publication, with information on living languages of the world. In 2018, Ethnologue delivered information on more than 7000 languages. This included the number of speakers, locations, dialects, and much more.
Previously, in 1984, Ethnologue, released a three-letter coding SIL system to identify languages it described. The SIL system greatly influenced the ISO 639 language code standards. Interestingly, the Ethnologue has been using the ISO standard since its 15th publication.
ISO language codes are the standard for linguistic codification worldwide. The most famous standard sets are ISO 639 (and the subsets ISO 639-1, ISO 639-2, ISO 639-3) for language codes, and ISO 15924 as standardization of language scripts. We discussed previously the ISO 15924 in our article on languages with dual alphabets. In this article, however, we will focus more on the ISO language codes 639.
The IETF language tags are a code to identify human languages. Conveniently, IETF language tags depend greatly on ISO standard sets. They combine subtags from ISO 639 for the language code, ISO 15924 for script, and use the ISO 3166-1 standard for country codes and UN M.49 for country or areas.
Although IETF language tags may seem daunting at first glance, its structure has been standardized by the Internet Engineering Task Force (IETF).
As a result, IETF language tags are used by HTTP, HTML, XML, and many more.
Arguably most commonly referenced sets of language codes, ISO 639 lists have been developing in stages during previous 30 years. The very first ISO 639-1 appeared in 1988 (originally just ISO 639), followed by ISO 639-2 in 1989. The ISO 639-3 language set appeared in 2004, covering more than 7000 languages.
ISO standards were released by ISO (International Organization for Standardization), an international NGO dedicated to creating international guidelines, specifications, requirements etc. Their mission is to contribute to easier processing and distribution of knowledge, information, products and services in general.
In the first place, the idea was to provide language experts with a system that would allow them to identify and tag content with precision. Since then, use of language coding has expanded, and nowadays machine learning and natural language processing depend greatly on proper language codification. Here is how ISO 639 standards work.

The first ISO 639 set includes identifiers for major languages from the world. Consequently, that covers languages that most frequently appear in the world literature and highly developed languages, with a specialized vocabulary and terminology.
The ISO 639-1 standard is a two-character code; one code per language from the original ISO 639 macro language list. The International Information Center for Terminology (Infoterm) is in charge of maintaining the ISO 639-1.
The ISO 639-2 firstly includes identifiers for languages from the 639-1 and additional languages which have a relevant amount of literature. This list provides identifiers for language families, and so covers almost all languages of the world.
This is a three-character code. The Library of Congress maintains the ISO 639-2.
The ISO 639-3 list covers individual languages from ISO 639-2, but includes also extinct, ancient, historic, and constructed languages (conlangs). This language code set recognizes the lesser-known languages. As a result, the alpha-3 codes largely overlap with ISO 639-2 codes.
ISO 639-3 is maintained by SIL International. According to SIL, language identifiers in ISO 639-3 were created with the use in computer systems in mind. The conclusion is that computer systems require a support for a large number of languages - the more, the better.
ISO/DIS 639-4: Codes for the representation of names of languages - Part 4: Implementation guidelines and general principles for language coding, general guidelines for use of ISO 639
ISO/DIS 639-5: Codes for the representation of names of languages - Part 5: Alpha-3 code for language families and groups - provide a 3 letter code for language families and groups (living and extinct)
ISO/CD 639-6: Codes for the representation of names of languages - Part 6: Alpha-4, Code for the comprehensive coverage of language variants.
Although the ISO language code sets cover almost all existing languages, not all languages appear in each ISO 639 part. Here is a comprehensive chart of which type of languages you can find in which ISO 639 set.
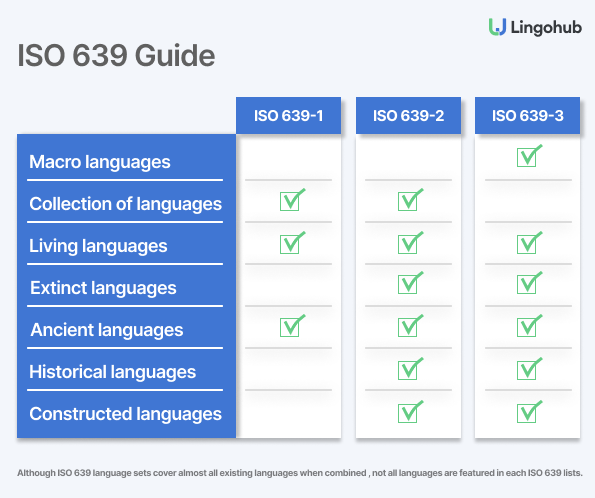
ISO 639-2 and ISO 639-3 use different criteria for dividing languages. While ISO 639-2 uses as a common denominator shared writing systems and literature, ISO 639-3 focuses on mutual ease of understanding and shared lexicon.
Macro Languages are essentially a mechanism that helps navigating language codes between ISO 639-1, ISO 639-2 and ISO 639-3.
For example, Chinese is a macro language that includes many languages but which are not mutually easy to understand. Urdu and Hindi do not form a macro language. Consequently, even dialects of Hindi are fall under separate languages.
Collection of languages is not the same as Macro Languages. In its essence, collective languages are language groups that do not satisfy the ISO criteria for a separate language code.
These collections of languages are excluded from ISO 639-3 because they never refer to an individual language, and most collective languages are included in ISO 639-5.
There are four special codes in ISO 639-2 and ISO 639-3 for cases where featured language codes are not applicable.
mis - Miscellaneous, or uncoded language code, is the perfect tag for languages not currently available in the ISO standards.
mul - Multiple languages code is useful in cases where data is available in more than one language.
und - Undetermined code is perfect for cases where the language is unknown.
zxx - No linguistic content/ not applicable code is great for data which is not actual language, for example onomatopoeia.
Simplicity is often the key, but Macro Languages featured in ISO 639-1 aren’t always the right choice. Here are some things to take into account when choosing the right language code for localization:
Will you be able to reach your target audience with a macro language?
Is your audience’s language region-specific? Is there a language variant that exists in several different territories?
Does your localization project require different scripts for the same language?
Managing language codes can be a daunting task, which is why we have language code support for our LingoHubbers ready. You can check the full guidelines to make the most out of your localization choices in our blog post. Additionally, our comprehensive Language designators list is regularly updated and easy to navigate.
If you have any doubts, feel free to contact our support team, and they will help you make the right choice for your project.

Beyond the basics: Navigating language codes for true localization
Language codes are the backbone of true localization. Discover how ISO 639 standards and regional variants shape global user experiences in our blog article.

LingoHub support for language codes in localization
Read in our blog about multiple language codes (ISO) LingoHub supports. Learn more about the ISO codes, their types, exceptions, and legacy encoding.

What are ISO 639 language codes?
Learn what ISO 639 language codes are, how they standardize language identification, and why they are essential for localization and multilingual software.
)