Overview of string comparison methods
Localization workflows & operations

Table of content
In the translation industry, there are several methods to compare strings or text segments. Comparisons are important for translation service providers (TSPs) and their price calculations. Two main comparisons can be identified for strings, source and target comparisons. Source comparisons, as the name suggests, compare two source text segments, while target comparisons compare two target text segments. Regardless of what is compared, source or target, various algorithms can be used to find the similarity or difference between text segments. We’ll take a closer look at four different algorithms today.
The Levenshtein Distance is the amount of single character edits needed to change a source word to a target word. Three edit types are performed by the algorithm: insert, delete or substitute. Let’s look at some examples below:
We want to calculate the Levenshtein Distance between cat and hat.
Source word | Edit | Target after edit |
cat | Substitute c with h | hat |
Since one substitution was necessary, the distance is 1.
We want to calculate the Levenshtein Distance between Cooperation and operation.
Source word | Edit | Target after edit |
Cooperation | Delete C | ooperation |
ooperation | Delete o | operation |
Since two deletions were necessary, the distance is 2.
We want to calculate the Levenshtein Distance between This is a car. and This is a red car..
Source word | Edit | Target after edit |
This is a car. | Insert “ “ (whitespace) | This is a car. |
This is a car. | Insert r | This is a r car. |
This is a r car. | Insert e | This is a re car. |
This is a re car. | Insert d | This is a red car. |
Since 4 insertions were necessary, the distance is 4.
If you want to learn more about the Levenshtein Distance, take a look at the Wikipedia page or try it out yourself with this distance calculator.
Similar to the Levenshtein Distance, the Longest Common Subsequence (LCS) distance uses the methods of insert and delete, but not substitute. It searches for the longest common subsequence between sequences or strings. The distance or result is the number of equal characters between the compared strings. You can find some examples below:
String 1 | String 2 | LCS distance |
cat | hat | 2 (“at”) |
ABCDEF | ZAYBXCWD | 4 (“ABCD”) |
This is a test | This is a text | 13 (“this is a tet”) |
This is some text that will be changed. | This is the new text. | 15 (“This is e text.”) |
Note: The last sequence could also be handled as full words instead: The return would then be:
String 1 | String 2 | LCS distance |
This is some text that will be changed. | This is the new text. | 13 (“This is text.”) |
The Jaro-Winkler Similarity algorithm is a variant of the Jaro Distance. It uses a prefix scale, strings that match from the start (prefix) for a defined length are favored. The similarity value ranges between 1 and 0. A rating of 1 shows that the two compared strings are identical, 0 means the strings have no similarity. The value is calculated using the predefined formula for the algorithm. You can find some examples below:
String 1 | String 2 | Jaro-Winkler Similarity |
cat | hat | 0.777778 |
Cooperation | operation | 0.939394 |
This is a car. | This is a red car. | 0.929864 |
This is a car. | You are looking at a vehicle. | 0.413793 |
If you want to learn more about the Jaro-Winkler Similarity, take a look at the Wikipedia page or check out these implementations over here.
Lastly, let’s look at the cosine similarity. In trigonometry, the cosine is the angle between two sides of a right triangle. For a specified angle, the cosine is the ratio of the length of the adjacent leg to that of the hypotenuse. Check out the image below.
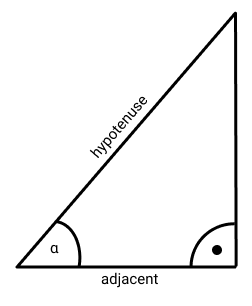
For the cosine similarity, the angle between two text segments is compared. To do this, however, the sentences need to be converted to vectors first. And that’s possible by creating a vector space for each sentence. A vector space has several dimensions, for each different word in the sentence a dimension is needed. Then the angle between the text segments can be calculated. A cosine can only range between -1 and 1, and to make things easier, the cosine similarity is often bound to only positive values. Sentences that are orthogonal (the angle is 90°) have a cosine similarity of 0. They are 100 % different. On the other hand, if the cosine similarity is 1, the angle is 0° and the sentences are 100 % alike. Their vectors are parallel or identical.
If you want to learn more about cosine similarity, check out this article on Wikipedia or this example of a python implementation.
In a future blog post, we’ll talk more about language service providers and calculations, so stay tuned!
Are you not using LingoHub yet? Try it out; it’s entirely free for 14 days, and all features are available to you during your trial. Feel also free to book a demo, or reach out to us anytime, simply contact our support.

The evolution of LSP (language sevice providers)
Learn how language service providers evolved, what services they offer, how the industry has changed, and what the future may hold for global communication.

Five benefits of professional translators for business
Professional translators greatly impact business success and content quality; read details about their importance in our article.
Languages in use per country - Checklist
Many countries have more than one official language, but the linguistic world just gets more complicated from there.
